
Es importante saber como hacer correctamente nuestras request dentro de nuestras aplicaciones, pero también es importante conocer que está sucediendo
detrás de estas mismas.
HTTP (Protocolo de transferencia de hipertexto) es un conjunto de reglas utilizado para intercambiar información en la web.
Cuando se inicia una solicitud, ya sea porque el usuario ha ingresado una URL en la barra de navegación o mediante el uso de las funciones "fetch" o "axios",
comienza un proceso. Pero, ¿qué es exactamente una URL?
URL: Universal resource locator -> Tiene tres partes.
-
Scheme: Es el HTTP, donde le dices al navegador que use ese protocolo para conectarse.
-
Host: Sirve para localizar el IP del servidor.
-
Path: Es el recurso que queremos de ese servidor.

Con el URL, el navegador necesita buscar el IP, y eso se hace a través de un proceso que se llama DNS Look Up.
DNS: Sistema de nombres de dominio -> Es como una agenda de direcciones de Internet que vincula dominios con direcciones IP. El proceso de búsqueda en el
DNS es complejo y utiliza varias capas de caché para agilizarlo, pero básicamente funciona así: El navegador busca la dirección IP en su propia caché, si
no la encuentra, continúa buscándola en la caché del sistema operativo y, si aún no la encuentra, realiza una o varias solicitudes para obtenerla.
Una vez que obtiene la dirección IP, el navegador inicia una conexión inicial a través del protocolo TCP/IP, que es el antecesor de HTTP, y esto se conoce
como handshake.
Los navegadores modernos utilizan una técnica llamada keep alive connection, que permite mantener la conexión abierta para realizar múltiples solicitudes
con una única conexión, evitando así repetir el proceso de establecimiento de conexión.
Una vez que se establece la conexión, se envía la solicitud HTTP, la cual incluye el método utilizado (por ejemplo, GET, POST, DELETE, PUT, etc.),
la URL del recurso solicitado, cualquier encabezado necesario y el contenido de la solicitud en el cuerpo. El servidor recibe la solicitud junto con toda la
información proporcionada en los encabezados, cuerpo e incluso en la URL misma, a través de los query parameters. Luego procesa la solicitud y envía una
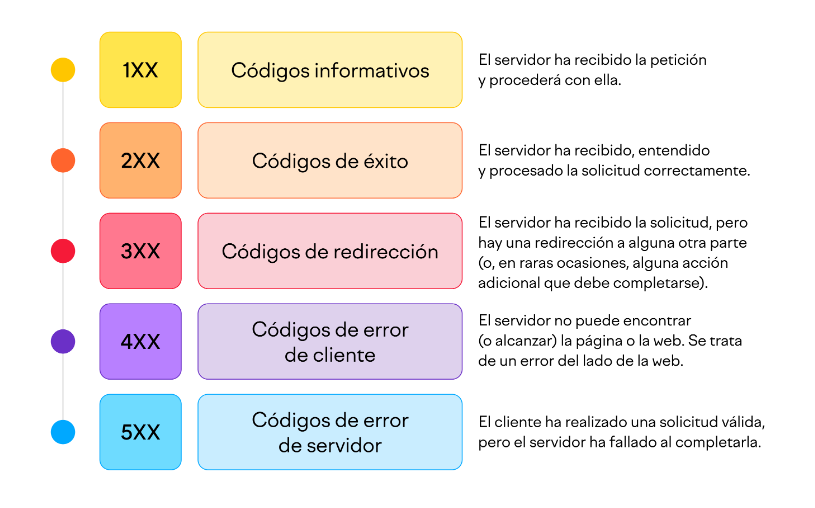
respuesta. Esta respuesta incluye un código de estado, como por ejemplo 200 si todo fue exitoso, 400 si no se pudo encontrar el recurso o 401 si la
autorización es incorrecta. La respuesta también puede contener información adicional, como encabezados (headers), cookies u otros elementos.
Cuando el navegador recibe la respuesta, la API fetch de JavaScript convierte esta respuesta en una promesa que se resuelve en un objeto de tipo "response".
Luego se puede utilizar el método .json() para convertir el contenido de la respuesta en un objeto JSON. Si la solicitud se realizó mediante axios,
el proceso es ligeramente diferente, aunque igualmente se recibe una promesa. Si la solicitud la hizo el navegador, se inicia todo el proceso de descarga,
análisis de archivos, ejecución de código, etc.
En resumen, cuando realizas una solicitud HTTP desde JavaScript, ocurren diversas acciones en segundo plano, como la resolución de la URL y la búsqueda en el DNS. Luego se envía la solicitud y se espera la respuesta. Cada paso es fundamental para la comunicación web mediante HTTP. Como desarrollador, comprender este proceso te permitirá depurar tu código, detectar errores más rápidamente y brindar una mejor experiencia a tus usuarios. En general, te convertirás en un mejor desarrollador. 🧑💻